Info
CVPR 2023
Xi’an Jiaotong University、Xidian University
代码地址:https://github.com/John-niu-07/BPE
Abstract
众所周知,深度神经网络(DNN)既容易受到后门攻击,也容易受到对抗攻击。在文献中,这两类攻击通常被视为不同的问题并分别解决,因为它们分别属于训练时攻击和推理时攻击。然而,在本文中,我们发现了它们之间一个有趣的联系:对于一个植入后门的模型,我们观察到其对抗样本与其后门图像具有相似的行为,即两者都激活了相同的DNN神经元子集。它表明,在模型中植入后门将显著影响模型的对抗样本。基于这些观察结果,我们提出了一种新的渐进式后门擦除(Progressive Backdoor Erasing, PBE)算法,通过利用非目标对抗性攻击来逐步净化受感染的模型。与以前的后门防御方法不同,我们方法的一个显著优势是,即使在干净的额外数据集不可用的情况下,它也可以擦除后门。我们的实验表明,对于5种最先进的后门攻击,我们的PBE可以有效地擦除后门,而对干净的样本没有明显的性能下降,并且性能优于现有的防御方法。
Key Insight
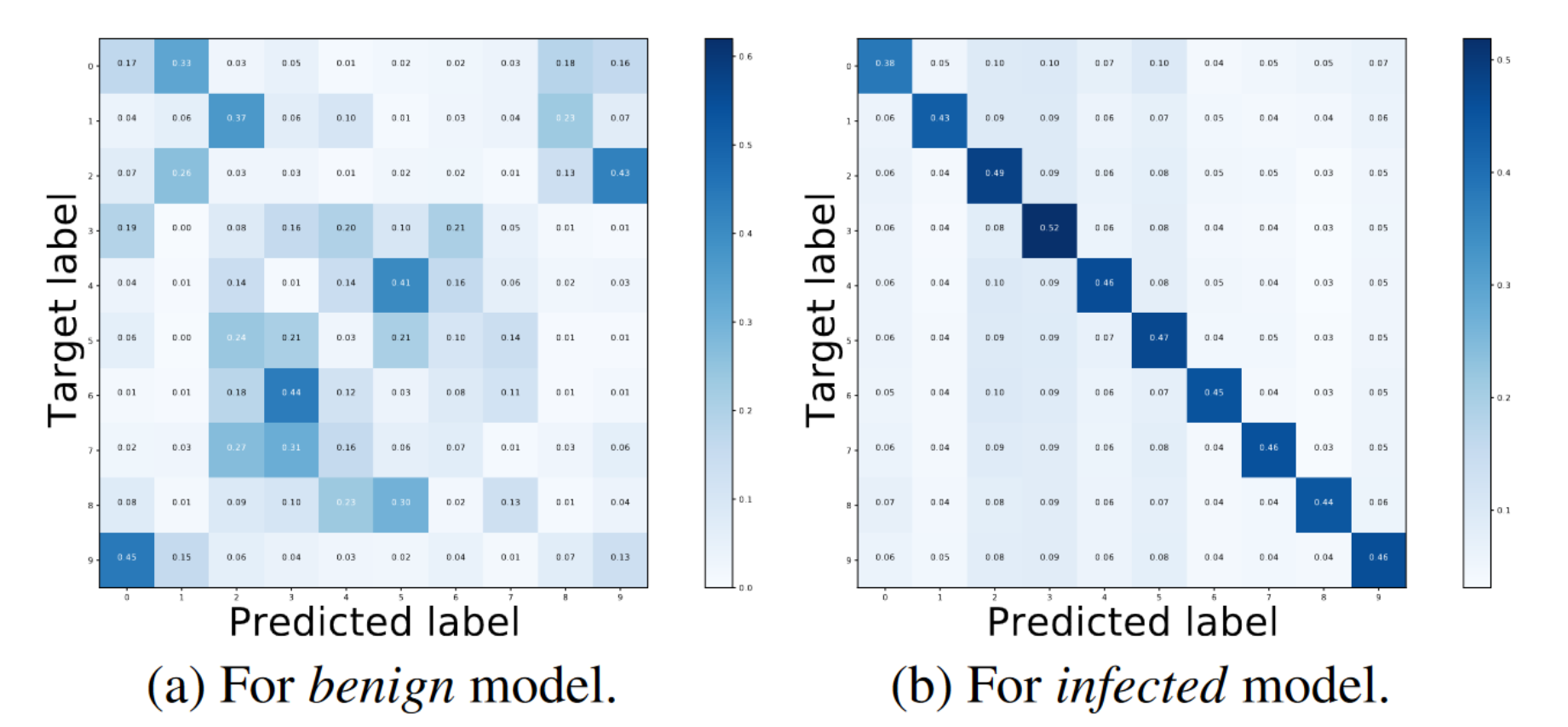
现在有两个模型,一个是干净模型benign,一个是被植入了WaNet后门的infected(无论是一个All-to-All模型还是十个All-to-One模型结果都显著,见原文4.3),然后使用10000张随机的CIFAR-10图像对这两个模型分别进行对抗攻击,结果发现得到的结果截然不同:对于benign模型,如下图的(a)所示,对抗样本被随机均匀地分类为不同的label,而对于infected模型来说,对抗样本被分类的label与后门的target label高度相关,如图(b)所示,与其他类别相比,它更有可能被分类为目标类。众所周知,后门样本也会被后门模型分类为target label(废话),因此后门模型的对抗样本可以视为其后门样本,也就是原文所说的"后门模型的对抗样本与其后门图像具有相似的行为"。
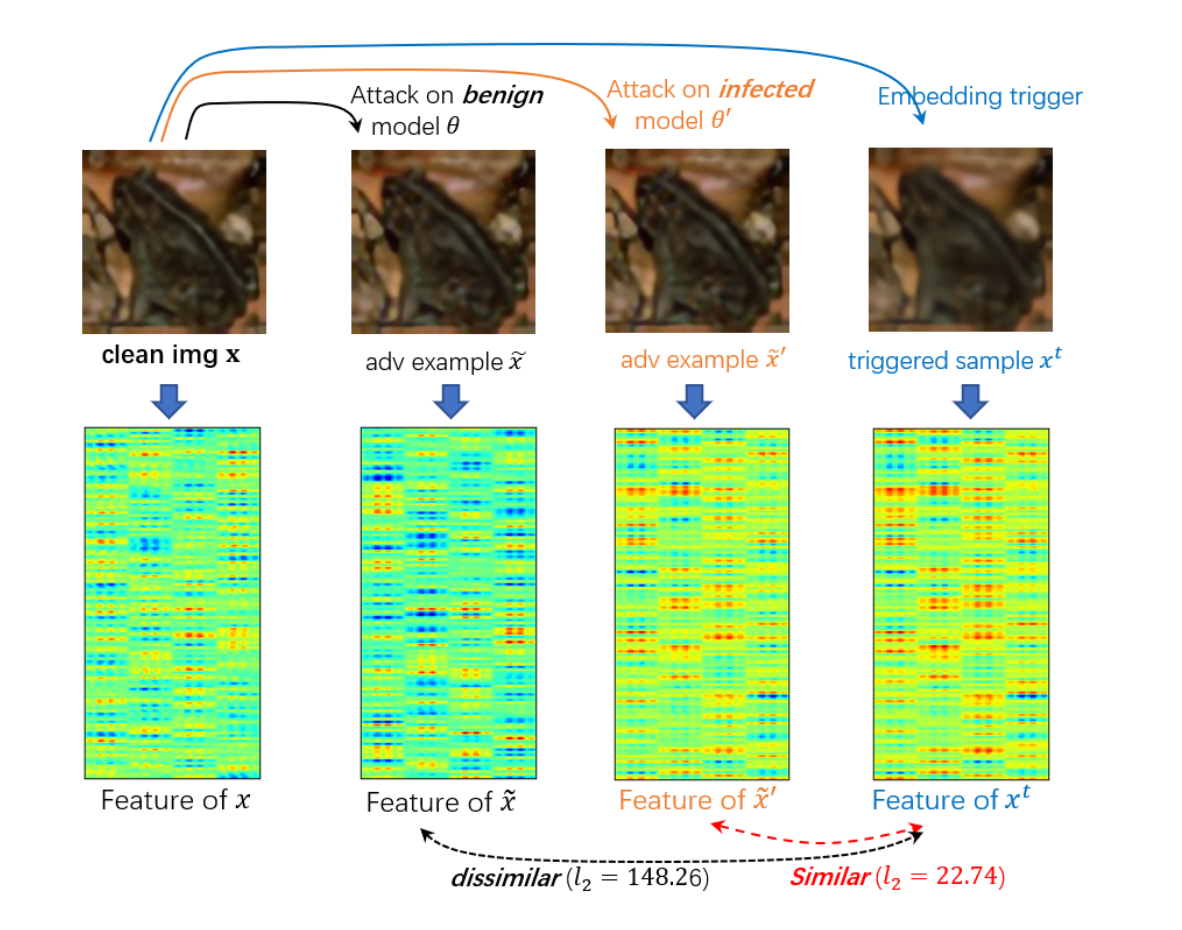
为了进一步验证作者的猜想,作者测量了不同图像之间的特征相似度,如下图,我们有干净图像x,干净模型的对抗样本$\widetilde x$,后门模型的对抗样本$\widetilde x ^{\prime}$,以及后门图像$x^t$,通过比较他们特征图的$l_2$距离,显然,后门图像$x^t$和$\widetilde x ^{\prime}$的距离远小于它和对抗样本$\widetilde x ^{\prime}$之间的距离,也就是说,我们可以将后门模型的对抗样本$\widetilde x ^{\prime}$当作后门图像$x^t$来使用,这是本文的方法的核心。对于这一发现,作者给出的解释是:“当后门植入模型时,一些DNN神经元会被触发激活,称为’后门神经元‘。当对受感染的模型进行对抗攻击时,这些‘后门神经元’更有可能在生成对抗性示例时被选择/锁定和激活。”
Theoretical Analysis
假设有一个线性模型,权重为$W=(w_1,w_2,…,w_K)$,后门模型的权重则为$\widetilde W ^\ast=(\widetilde w_1,\widetilde w_2,…,\widetilde w_K)$,后门图像为$x^t = x + P$,假设在扰动$\tau > 0$的影响下我们的线性模型也可以正确分类,并且这个$\tau$足够大,以至于小扰动不影响分类结果。
在上面的假设下,我们有扰动$r$,以及其在P方向上的投影$r_ \perp$,那么它有下界:
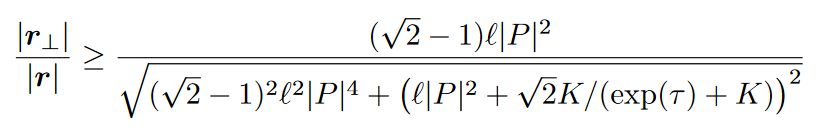
上述公式可以看出,当将扰动$r$投影在触发P的方向上时,投影$r_ \perp$在完整的扰动$r$中占据了重要的部分。这意味着扰动$r$与触发P非常相似,这证明了我们的观察是合理的。
Thread Model
假设攻击者可以控制训练数据并且已经将后门植入到模型之中。
在本文中,有两种防御设定。一种类似于其他”模型修复“,拥有感染模型和一个额外的干净数据集,还有一种类似于”数据过滤“,可以访问训练数据集,但是没有额外的干净数据集。
Method
如算法1所示,渐进式后门擦除PBE大致可以分为三步,假设现在可以访问训练数据集但是没有额外的干净数据集。
- 首先,从训练集中随机采样一些图像(可能有后门图像也可能有干净图像)作为初始数据集$D_{ext}^0$,然后利用这些图像对后门模型$\theta^{\prime}$进行无目标对抗攻击,得到相应的对抗样本$\widetilde x ^{\prime}$,在前面的key insight中我们已经发现后门模型的对抗样本$\widetilde x ^{\prime}$可以视为后门图像$x^t$,也就说我们现在得到了标签是干净的后门图像(由于目前的后门攻击中投毒率已经越来越低,因此抽取的图像全是后门图像的概率并不大),因此我们可以使用这些图像将后门模型之前学习的后门信息”纠正过来“,于是开始第一次fine-tuning,这一步目的是为了降低ASR。
- 在第t次迭代中我们有额外数据集$D_{ext}^t$,前面说过这个数据集从训练集中随机采样得到,因此有一部分图像是干净的,我们可以利用这些图像进行第二次fine-tuning,这一步的目的是提高ACC。
- 额外数据集$D_{ext}^t$中显然会有后门图像,这些图像无论是对于第一步降低ASR还是第二步提高ACC都会产生负面影响,因此这一步的目的是尽可能剔除$D_{ext}^t$中的后门图像,得到更干净的$D_{ext}^{t+1}$。这一步的原理是我们有原始的后门模型$\theta^{\prime}$,还有一个上一步得到的更加干净的模型$\theta^{t}$,显然后门图像在这两个模型中的表现不同,而干净图像则应该表现一致,由于模型$\theta^{t}$不一定足够干净,因此根据模型输出的每个类别的概率进行判断,而不是仅仅看predicted label,至此,我们得到更加干净的数据集$D_{ext}^{t+1}$,回到第一步,进行下一轮迭代,最终得到净化模型$\theta^{T}$。
如果是第一种有额外的干净数据集的设定,那么可以直接跳过第三步,只需要运行第一步和第二步一次即可,称之为对抗微调(Adversarial Fine-Tuning, AFT)。

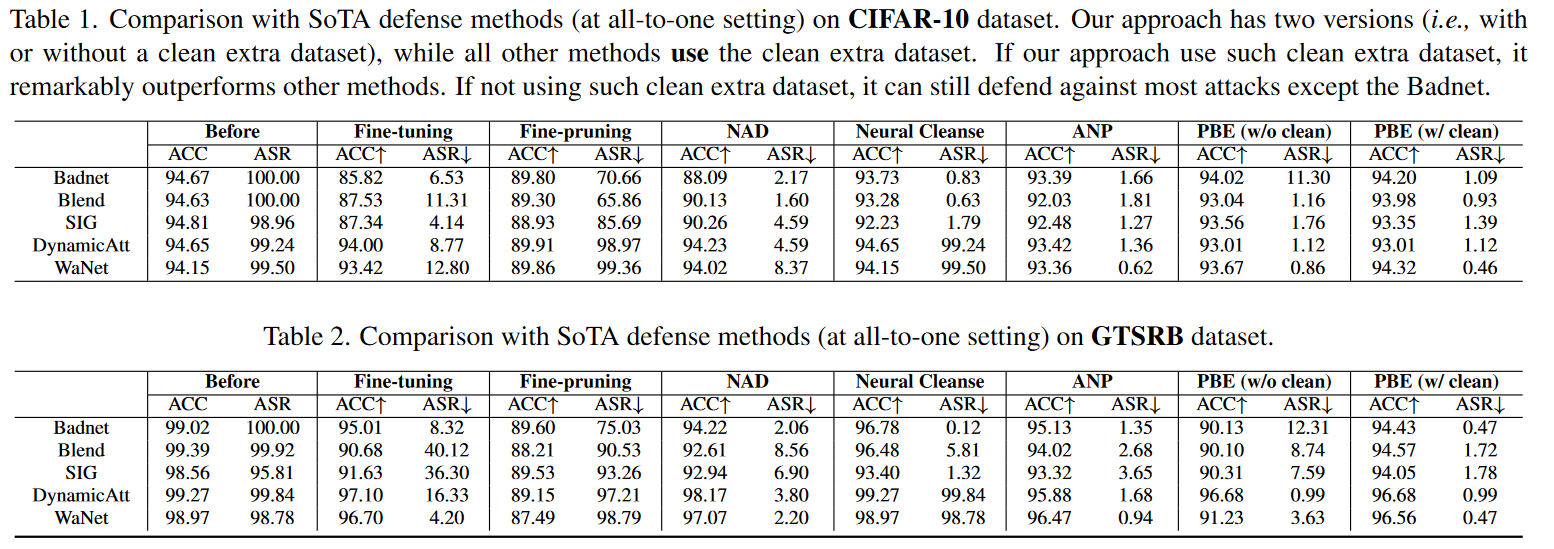
Experiment
对比了若干防御方法在若干攻击方法上面的效果,数据集只有两个,分别是CIFAR-10和GTSRB,结果如下: